全文检索/搜索引擎 Elasticsearch
教学目标
- 了解Elasticsearch的应用场景
- 掌握索引维护的方法
- 掌握基本的搜索API的使用方法
一、Elasticsearch介绍
1.介绍

es是一个基于Lucene的高扩展的分布式搜索服务器,支持开箱即用
es隐藏了Lucene的复杂性,对外提供了Restful接口来操作索引,和实现搜索
es优点:1.扩展性很好,可以部署上百台服务器集群,处理PB级别的数据 2.近实时的去索引数据,搜索数据
2.solr和es
1
2
3
4
5
6
| 如果你的公司在用solr可以满足需求就不需要换了
如果你的公司准备进行全文检索项目的开发,建议优先考虑es,因为Github这样大规模的搜索都在使用它,包括国内百度、腾讯也在用它
如果数据规模不是特别大,用solr比es好,
但是数据规模变的特别大,es的表现会比solr更好一些
|
3.原理与应用
3-1 索引结构
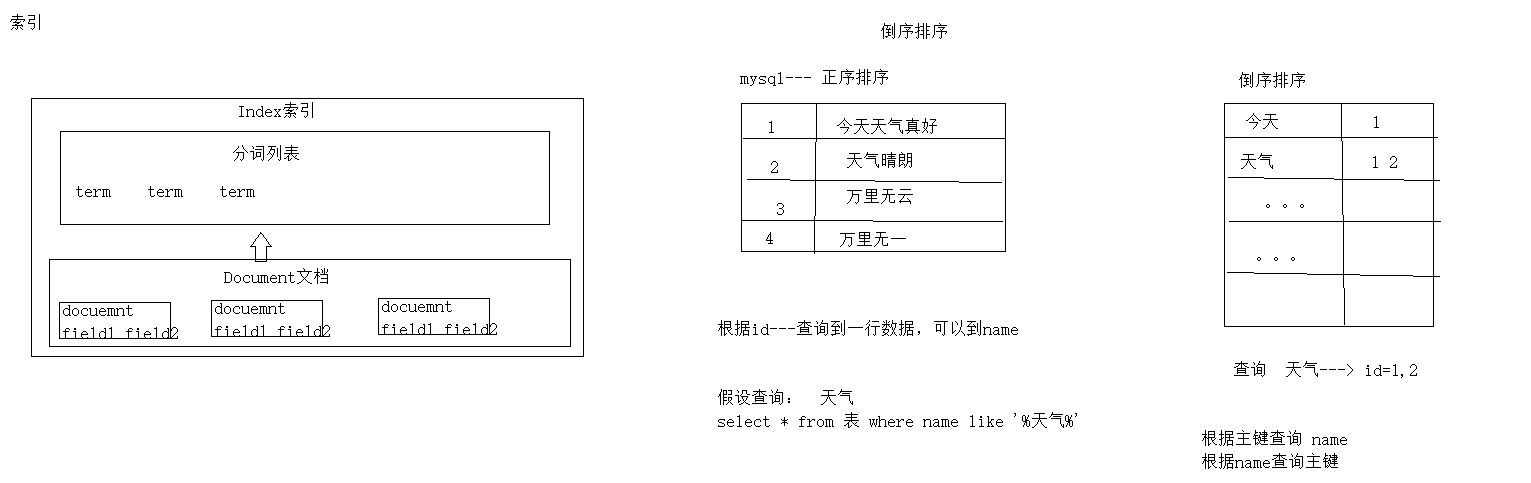
逻辑结构部分是一个倒排索引表
1.将搜索的文档内容分词,所有不重复的词组成分词列表
2.将搜索的文档最终以Document方式存储起来
3.没歌词document都有关联
3-2 如何使用es
如果使用的是Lucene或solr,那么你只能使用java程序去操作它,而使用es可以无视应用技术
es提供Restful API接口进行索引、搜索,并且通过这种方式可以支持多种客户端
二、es安装
1.下载镜像
1
| docker pull elasticsearch:6.5.4
|
2.创建容器
1
| docker run -d -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" --name=myes -p 9200:9200 -e "discovery.type=single-node" 93109ce1d590
|
es 的运行默认要求是1G内存,所以需要调整jvm参数
3.访问测试
http://192.168.25.134:9200/
三、Restful Api
1.ES的体系结构
| Mysql |
Elasticsearch |
| database(数据库) |
index(索引) |
| table(表) |
type(类型) |
| row(行) |
document(文档) |
2.创建索引
创建articleindex 的索引
Method: put
url:http://192.168.25.134:9200/articleindex/
3.创建类型和文档
method: post
url: http://192.168.25.134:9200/articleindex/article
1
2
3
4
| >{
"title":"SpringBoot3.0",
"content":"新的版本3.0发布了"
>}
|
响应结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| {
"_index": "articleindex",
"_type": "article",
"_id": "AbJsVoUBEzhKOzQVNuuC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
|
4.查询全部文档
method: get
url:http://192.168.25.134:9200/articleindex/article/_search
响应结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| {
"took": 100,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.0,
"hits": [
{
"_index": "articleindex",
"_type": "article",
"_id": "AbJsVoUBEzhKOzQVNuuC",
"_score": 1.0,
"_source": {
"title": "SpringBoot3.0",
"content": "新的版本3.0发布了"
}
},
{
"_index": "articleindex",
"_type": "article",
"_id": "ArJuVoUBEzhKOzQVNetE",
"_score": 1.0,
"_source": {
"title": "SpringBoot已经一统天下",
"content": "springBoot全家桶时代已经到来"
}
}
]
}
}
|
5.修改文档
method: put
url:http://192.168.25.134:9200/articleindex/article/ArJuVoUBEzhKOzQVNetE
1
2
3
4
| {
"title": "SpringBoot全家桶",
"content": "springBoot已经一统天下了"
}
|
响应结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| {
"_index": "articleindex",
"_type": "article",
"_id": "ArJuVoUBEzhKOzQVNetE",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
|
6.删除文档
method:delete
url:http://192.168.25.134:9200/articleindex/article/ArJuVoUBEzhKOzQVNetE
返回结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| {
"_index": "articleindex",
"_type": "article",
"_id": "ArJuVoUBEzhKOzQVNetE",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
|
7.根据id查询
method:get
url:http://192.168.25.134:9200/articleindex/article/A7J3VoUBEzhKOzQVI-vG
返回结果
1
2
3
4
5
6
7
8
9
10
11
| {
"_index": "articleindex",
"_type": "article",
"_id": "A7J3VoUBEzhKOzQVI-vG",
"_version": 1,
"found": true,
"_source": {
"title": "SpringBoot全家桶",
"content": "springBoot已经一统天下了"
}
}
|
8.基本匹配查询
按照某个列(非id)查询
需求:根据title查询,只要title中包含全家两个字就查询出来
method: get
url:http://192.168.25.134:9200/articleindex/article/_search?q=title:全家
返回结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| {
"took": 77,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1.0608165,
"hits": [
{
"_index": "articleindex",
"_type": "article",
"_id": "BLJ6VoUBEzhKOzQVResb",
"_score": 1.0608165,
"_source": {
"title": "百事可乐全家欢",
"content": "喝百事可乐开心过大年"
}
},
{
"_index": "articleindex",
"_type": "article",
"_id": "A7J3VoUBEzhKOzQVI-vG",
"_score": 0.5753642,
"_source": {
"title": "SpringBoot全家桶",
"content": "springBoot已经一统天下了"
}
}
]
}
}
|
9.模糊查询
需求:查询title中含有3字的内容
method: get
url:http://192.168.25.134:9200/articleindex/article/_search?q=title:*3*
备注: * 代表任意的字符串
四、es的第三方视图
mysql —>naivcat SqlYog sqlManage
https://github.com/mobz/elasticsearch-head
通过谷歌浏览器中添加插件,是不需要处理cors的问题
五、分词
1.英文分词
method: post
url:http://192.168.25.134:9200/_analyze
1
2
3
4
| {
"analyzer": "standard",
"text": "I love java,i love es"
}
|
在英文分词中是比较简答的,只要遇到了空格或者是标点符号,那么就认为是一个词
2.中文分词
在es中是不支持中文分词的,必须添加中文分词的插件
先上传ik分词器插件
将上传的ik分词器插件,复制到容器的plugins目录
进入到容器中
1
2
3
| [root@my-docker ~]
[root@cae3daa2c05a elasticsearch]
LICENSE.txt NOTICE.txt README.textile bin config data lib logs modules plugins
|
进入plugins目录
1
2
3
| [root@cae3daa2c05a elasticsearch]
[root@cae3daa2c05a plugins]
elasticsearch-analysis-ik-6.5.4.zip ingest-geoip ingest-user-agent
|
创建ik文件夹,然后将插件解压到ik目录
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| [root@cae3daa2c05a plugins]
[root@cae3daa2c05a plugins]
elasticsearch-analysis-ik-6.5.4.zip ik ingest-geoip ingest-user-agent
[root@cae3daa2c05a plugins]
[root@cae3daa2c05a plugins]
[root@cae3daa2c05a ik]
elasticsearch-analysis-ik-6.5.4.zip
[root@cae3daa2c05a ik]
[root@cae3daa2c05a ik]
[root@cae3daa2c05a ik]
[root@cae3daa2c05a ik]
[root@cae3daa2c05a plugins]
elasticsearch-analysis-ik-6.5.4.zip ik ingest-geoip ingest-user-agent
[root@cae3daa2c05a plugins]
|
重启es
1
2
3
4
| [root@cae3daa2c05a plugins]
exit
[root@my-docker ~]
myes
|
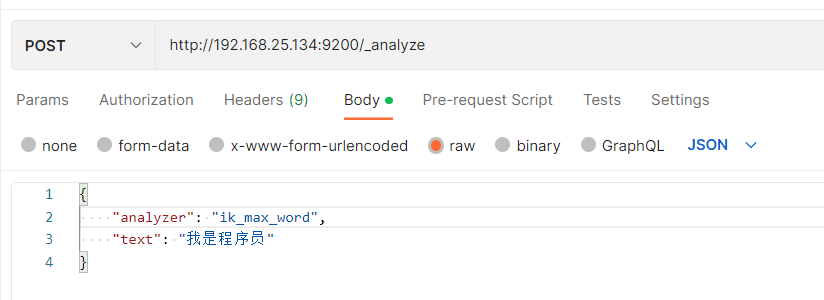
重新做分词测试
IK分词器有两种分词模式:
- 1.细粒度模式
ik_max_word
2.智能模式 ik_smart
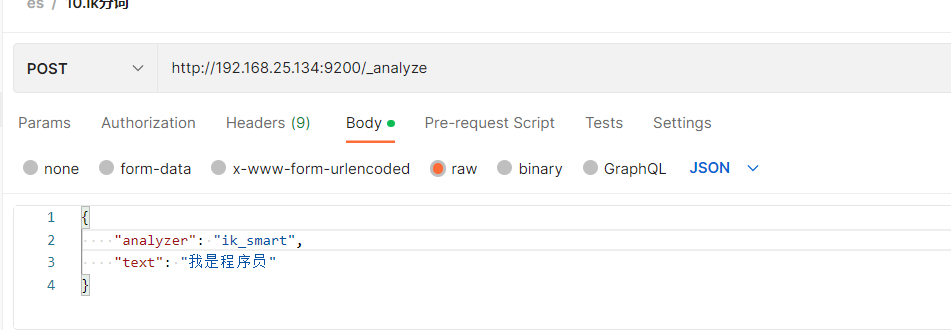
method: post
url:http://192.168.25.134:9200/_analyze
1
2
3
4
5
| {
"analyzer": "ik_smart",
"text": "I love java,i love es"
}
|
智能分词
细粒度分词